蚂蚁技术研究院今日宣布推出LLaDA2.0系列离散扩散大语言模型,并同步公开了背后的技术报告,宣称这是业内首个100B扩散语言模型。LLaDA2.0包含MoE架构的16B和100B两个版本,将Diffusion模型的参数规模首次扩展到了100B量级。
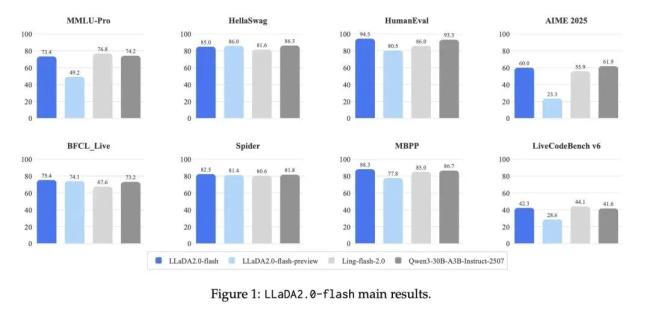
该研究院表示,此次发布的模型不仅打破了扩散模型难以扩展的固有印象,还在代码、数学和智能体任务上展现出了超越同级自回归模型的性能。通过创新的Warmup-Stable-Decay持续预训练策略,LLaDA2.0能够无缝继承现有自回归模型的知识,避免了从头训练的高昂成本。结合置信度感知并行训练和扩散模型版DPO,LLaDA2.0在保证生成质量的同时,利用扩散模型的并行解码优势,实现了相比自回归模型2.1倍的推理加速,证明了在超大规模参数下,扩散模型不仅可行,而且更强、更快。
蚂蚁技术研究院在知识理解、数学、代码、推理及智能体等多个维度对模型进行了评估。结果显示,LLaDA2.0在结构化生成任务(如代码)上具有显著优势,并在其他领域与开源自回归模型持平。LLaDA2.0的模型权重及相关训练代码已在Huggingface开源。