DeepSeek-R2曝5月前上线。第三天,DeepSeek发布了DeepGEMM。这是一个支持稠密和MoE模型的FP8 GEMM计算库,可为V3/R1的训练和推理提供强大支持。仅用300行代码,这个开源库就能超越专家精心调优的矩阵计算内核,为AI训练和推理带来显著性能提升。
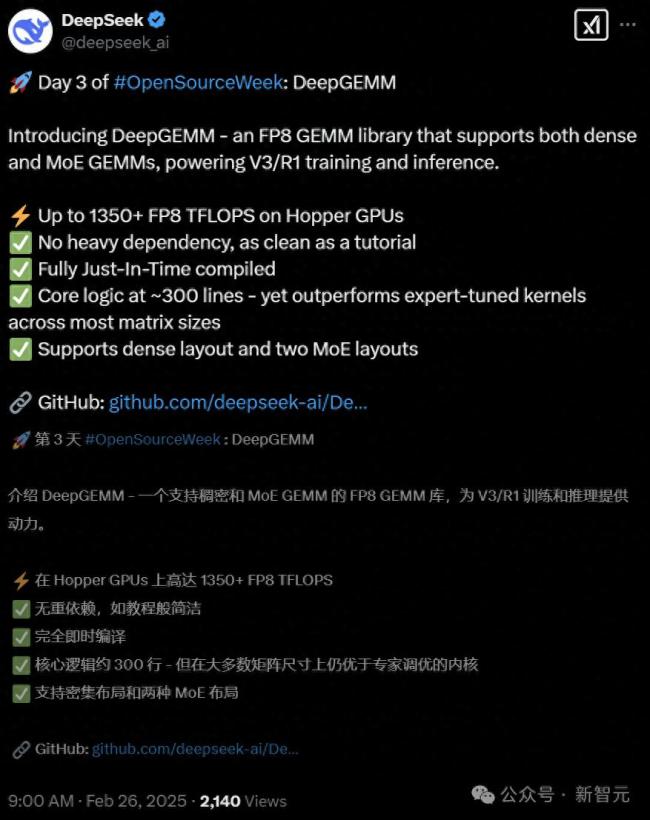
DeepGEMM库具有以下特点:在Hopper GPU上实现高达1350+ FP8 TFLOPS的算力;极轻量级依赖,代码清晰易懂;完全即时编译,即用即跑;核心逻辑仅约300行代码,却在大多数矩阵规模下超越专家级优化内核;同时支持密集布局和两种MoE布局。开发者惊叹于其简洁高效的设计,认为这可能是GPU运算技术的重大突破。
DeepGEMM改变了使用FP8 GEMM库的方式,简单、快速、开源,代表着AI计算的未来。在即将发布的DeepSeek-R2中,将实现更好的编码,并支持多种语言进行推理。业内人士预测,这将是AI行业的一个关键时刻。目前,DeepSeek已经在创建高成本效益模型方面取得成功,打破了该领域的垄断局面。DeepGEMM发布两天内,前两个项目FlashMLA和DeepEP分别获得了近10k和5k星标。
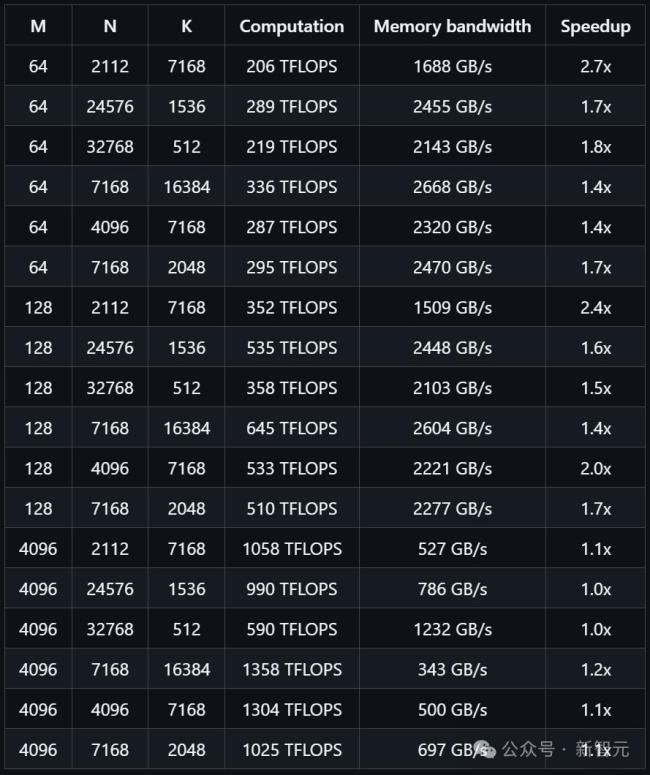
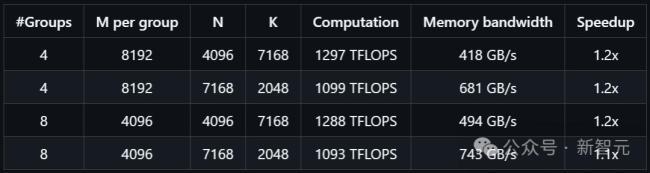
DeepGEMM专为清晰高效的FP8通用矩阵乘法设计,采用了DeepSeek-V3中提出的细粒度缩放技术。它支持常规矩阵乘法和混合专家模型分组矩阵乘法。DeepGEMM使用CUDA编写,通过轻量级即时编译模块在运行时编译所有内核。目前仅支持NVIDIA Hopper张量核,为了解决FP8张量核在累加计算时的精度问题,采用了基于CUDA核心的两级累加技术。尽管借鉴了CUTLASS和CuTe的一些概念,但避免了过度依赖它们的模板或代数系统,追求设计简洁,包含一个核心内核函数,代码量仅约300行。尽管采用轻量级设计,DeepGEMM在处理各种矩阵形状时的性能都能够达到甚至超越经专家调优的库。
研究人员在配备NVCC 12.8的H800上测试了DeepSeek-V3/R1推理过程中可能使用的所有矩阵形状(包括预填充和解码阶段),所有性能提升指标均与基于CUTLASS 3.6内部精心优化的实现进行对比计算得出。尽管某些矩阵形状下的表现还不够理想,但可以提交优化相关的拉取请求。
安装和测试指南如下:首先通过命令克隆仓库及其子模块,然后创建第三方库(CUTLASS和CuTe)的符号链接以便开发。接着测试JIT编译功能,最后测试所有GEMM实现。具体命令包括: ``` git clone --recursive gitgithub.com:deepseek-ai/DeepGEMM.git python setup.py develop python tests/test_jit.py python tests/test_core.py ```
接下来,在Python项目中导入deep_gemm即可开始使用。DeepGEMM中的内核采用线程束专用化技术,实现了数据移动、张量核心MMA指令和CUDA核心提升操作的重叠执行。利用TMA硬件特性实现更快速的异步数据移动。此外,采用完全即时编译设计,无需在安装时编译,所有内核在运行时通过轻量级JIT实现进行编译,有效节省寄存器空间,使编译器能够进行更多优化。对于某些形状,采用2的幂次对齐的块大小可能导致SM利用率不足,团队为此提供了非对齐块大小的支持,结合细粒度缩放技术,带来了显著的性能提升。