美国搜索引擎和AI巨头谷歌公司周三宣布产品线全面上新,所有用户正式迈入“Gemini 2.0”时代。其中,Gemini 2.0 Flash模型上线,这款模型适用于大规模、高容量、高频率任务。自去年12月推出以来,其风头被性价比更高的Deepseek-V3模型抢走。

为应对竞争,谷歌推出了名为Gemini 2.0 Flash-Lite的多模态大模型。该模型在大多数基准测试中表现优于上一代Gemini 1.5 Flash模型,并继续强调性价比。横向对比API价格,Gemini 2.0 Flash和Lite的输入价格分别为0.10美元/每100万Tokens和0.075美元/每100万Tokens。使用Gemini 2.0 Flash-Lite模型为4万张独特图片各生成一行标题,所需费用约为1美元。若击中缓存,价格将降至0.025美元/每100万Tokens(不包含音频)和0.01875美元/每100万Tokens。

相比之下,OpenAI的性价比模型gpt-4o-mini最低价格为0.075美元/每100万Tokens。而性能更强且更具性价比的DeepSeek-V3模型,在击中缓存的情况下只需0.014美元/每100万Tokens。不过,从2月8日开始,DeepSeek的价格将翻5倍至0.07美元/每100万Tokens。
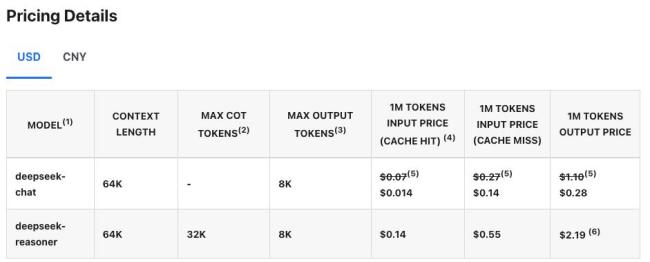
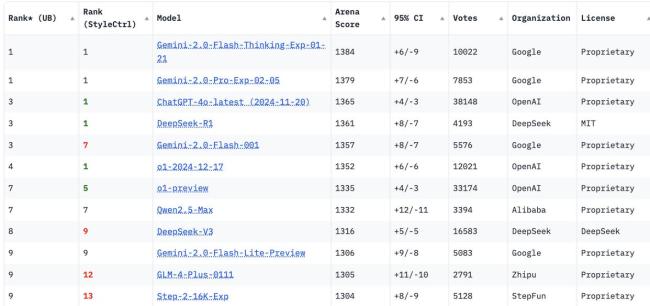
从基准测试数据来看,V3模型的多项指标与Gemini 2.0 Flash相近,均高于Gemini 2.0 Flash-Lite。此外,谷歌的模型具备处理图片、音频、视频信息输入的多模态优势。作为提升关注度的新尝试,谷歌还在Gemini应用中开放了Gemini 2.0 Flash Thinking模型。在最新榜单中,Gemini 2.0 Flash-Thinking总分排名第一,DeepSeek的R1模型略胜一筹。阿里巴巴的Qwen2.5-Max、DeepSeek-V3以及Gemini 2.0 Flash-Lite也都进入了前十名。
谷歌还推出了Gemini 2.0 Pro模型,声称它比以往任何Gemini模型都具有更好的世界知识理解和推理能力,在编程和处理复杂提示时表现出色。这款模型可以调用谷歌搜索工具并代表用户执行代码。Gemini 2.0 Pro的上下文窗口达到200万个Tokens,意味着可以一次性处理150万个英文单词的输入,相当于一次处理《哈利波特》系列的7本书后还能余下40万个单词。
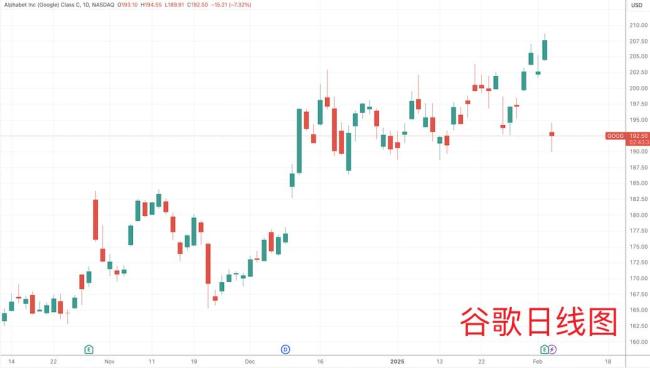
尽管发布了这些更新,谷歌股价仍下跌7%。主要原因是公司预期本财年资本支出高达750亿美元,主要用于扩展人工智能产品和建设数据中心,这一数字远超华尔街分析师预期的588亿美元。