科技圈从来不缺新闻,但 DeepSeek-R1 的出现却像一颗石子投入平静的湖面,激起了层层涟漪。这家来自中国的 AI 初创公司以其开源的推理大模型 R1 搅动了全球 AI 格局。R1 不仅性能媲美甚至超越 OpenAI o1,还以低廉的成本和开放的姿态赢得了全世界的关注。DeepSeek-R1 的开源策略和高效性能正在迫使整个行业重新思考 AI 的未来。
中国计算机学会青年计算机科学与技术论坛(CCF YOCSEF)近期组织了一场研讨会,邀请了复旦大学邱锡鹏教授、清华大学刘知远长聘副教授、清华大学翟季冬教授以及上海交通大学戴国浩副教授四位专家,从不同角度深入解析了 DeepSeek-R1 的技术突破与未来影响。
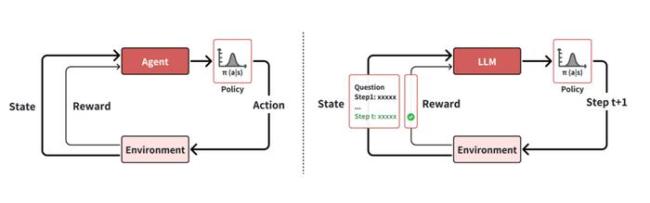
要理解 R1 的突破,需要从 o1 类推理模型说起。邱锡鹏认为当前人工智能领域正面临一个重要转折点。此前 Ilya 称“预训练时代可能即将结束”,主要源于数据增长的停滞。OpenAI 开始转向强化学习和推理式计算,试图通过增加推理长度来改进模型性能,为下一代大模型的发展注入新动力。
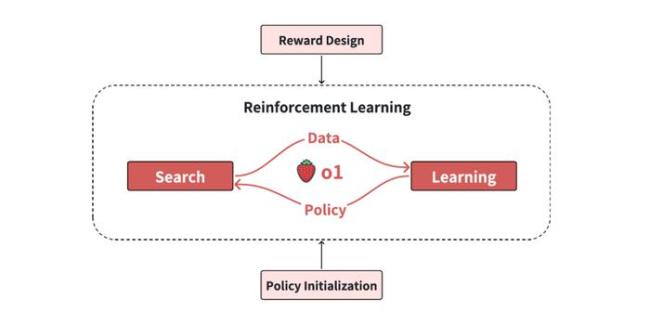
o1 模型的训练在强化学习框架下进行,大语言模型充当一个 Agent,每个动作生成下一个 token,最终生成整个 step 或 solution。o1 这类大型推理模型可以分为四个核心要素:策略初始化、奖励函数设计、搜索策略和学习过程。策略初始化要求模型具备初始的类人推理行为能力,包括问题理解、任务分解及验证和修正错误的能力。奖励函数设计则涉及从环境中直接获得奖励信号或通过专家偏好数据训练奖励模型。搜索策略包括基于树的搜索和基于顺序修改的搜索。学习过程主要包括使用强化学习和其他方法优化模型,分为预热阶段和强化学习阶段。
R1 发布了两个版本:R1-Zero 和 R1。R1-Zero 完全依靠强化学习驱动,不经过预热阶段,没有任何初始的人工调节。在训练过程中,随着步骤的增加,模型逐渐展现出长文本推理能力,尤其是长链推理,并表现出自我修正能力。不过也存在一些问题,如语言混合的问题。
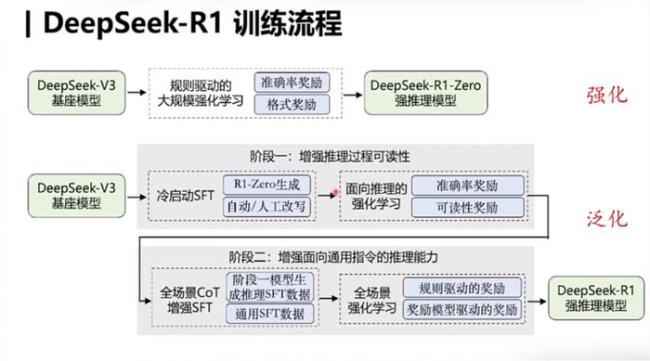
R1 的训练分为四个关键阶段:冷启动阶段、推理导向的强化学习阶段、拒绝抽样与监督微调阶段,以及全任务强化学习阶段。值得注意的是,R1 并未采用传统的过程监督或蒙特卡洛树搜索等技术,而是通过 majority vote 大幅提高推理效果。尤其令人意外的是,R1 在写作能力方面表现突出。
DeepSeek-R1 引起广泛关注的原因在于其独特的技术路线和开源策略。刘知远指出,DeepSeek 是全球首个通过纯强化学习技术成功复现 o1 能力并开源相关技术细节的团队。R1 基于 Deep Seek-V3 的基础模型,通过大规模强化学习增强推理能力,并将强推理能力泛化到其他领域。此外,DeepSeek 选择了开源的道路,这一决定具有深远的战略意义,展示了“有限算力+算法创新”的发展模式。
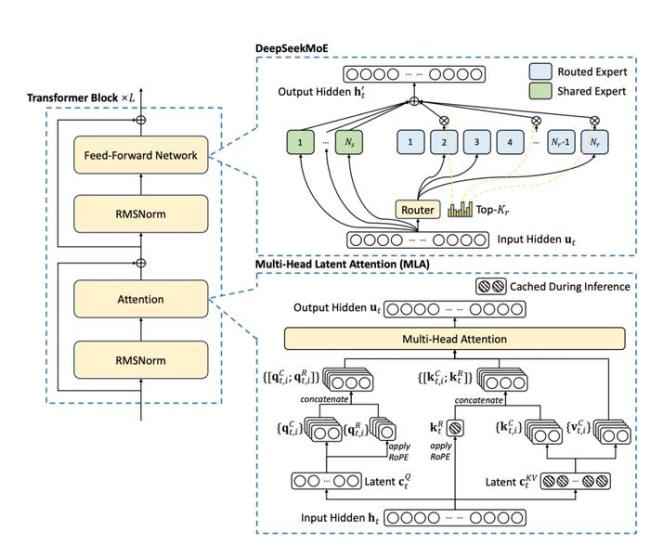
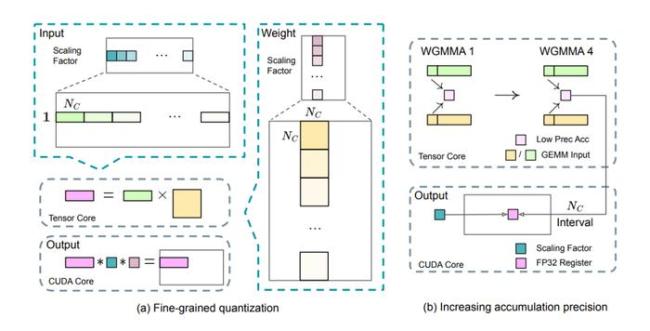
除了算法层面的创新,DeepSeek 降低训练成本的方法也是引起关注的重要原因。翟季冬从系统软件层面分析了 DeepSeek 降低训练成本的方法。DeepSeek 开发了并行训练框架 HAI-LLM,采用了 16 路流水线并行、64 路专家并行 (跨越 8 个物理节点) 和基于 ZeRO-1 的数据并行方案。DeepSeek 针对系统的负载均衡、通信优化、内存管理和计算优化进行了深度优化。

戴国浩从软硬件协同视角分析了 DeepSeek 的未来方向。他指出,了解硬件细节、极致底层优化、打通软件硬件、联合协同优化是关键。DeepSeek 的成功证明,通过系统架构的优化结合国产芯片和硬件,中国的 AI 技术完全可以逐步超越国际竞争者。
研讨会上,专家们讨论了 MoE 架构是否是当前最优解的问题。刘知远认为这是一个开放性的问题,技术在不断变化。翟季冬强调技术在不停地变化,新的技术可能会颠覆现有技术。戴国浩从历史角度分析了神经网络的发展,指出 MoE 在当前取得了不错的效果,但不是最优解。
DeepSeek-R1 的出现标志着 AI 领域格局的重要转变。美国目前仍占据领先地位,但形势正在发生微妙变化。DeepSeek 展现的高效创新路径或将重新定义 AI 发展的范式。