当硅谷仍在为GPU万卡集群投入巨额资金时,来自杭州的一群年轻人用557.6万美元证明,AI大模型的竞争并不只依赖规模,更看重使用效率。一款上架不到半个月的应用程序DeepSeek在1月27日登顶苹果应用商店排行榜,击败了ChatGPT。
最近几天,AI领域最火的大语言模型不是ChatGPT或文心一言,而是杭州AI公司深度求索推出的DeepSeek。从去年12月26日发布的DeepSeek-V3到1月20日的DeepSeek-R1,这家公司以OpenAI三十分之一的价格实现了与o1模型相当甚至超越的成绩,给美国AI行业带来了不小的冲击。
经过同题问答测试,DeepSeek-R1通过步步推理生成了具有逻辑性的回答,用户可以看到其思考过程。IT从业者刘鸿博表示,这种体验与第一次使用ChatGPT 3.5相似,甚至更加震撼。他认为DeepSeek对高语境内容和中文网络梗的理解能力更强,达到了脱口秀文本的水平。
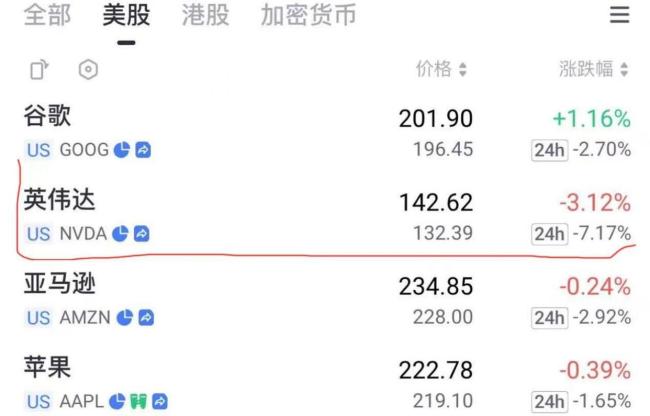
DeepSeek-R1发布后,不少美国AI从业者在社交平台上表达了内心的震撼。面对成本仅为“零头”但性能优秀的大模型,许多人发现传统的高投入模式已无法阻止用户的选择。北京时间1月27日,DeepSeek在美国、中国和英国的App Store免费应用下载榜上名列前茅。
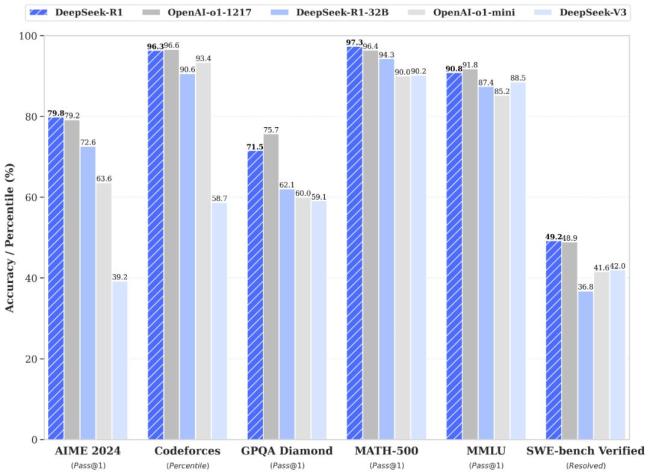
根据官方公布的性能测试,DeepSeek在数学测试、编程等多个领域与o1模型表现旗鼓相当,在某些测试中还超过了o1模型。此外,DeepSeek的训练成本更低,使用的算力也受到限制。相比之下,Meta旗下Llama3.1 405B模型的训练成本超过6000万美元,而OpenAI的GPT-4o模型的训练成本为1亿美元。
DeepSeek的价格优势早在去年年中就已显现,但由于当时知名度不高,降价声势很快被其他大厂盖过。现在,除了价格优势外,DeepSeek还有比肩o1模型的性能。一些业内人士认为,DeepSeek可能颠覆硅谷巨头的高投入路径,对那些依赖销售大量GPU的公司形成挑战。

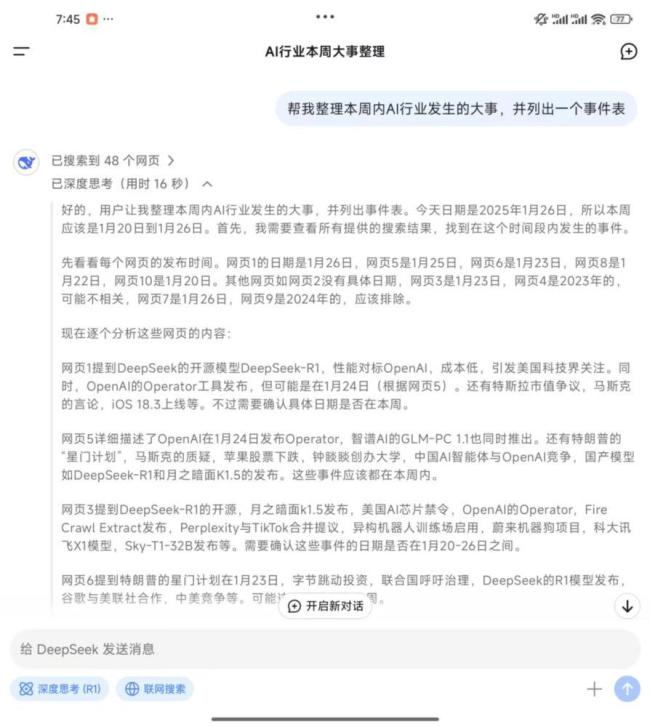
在实际应用方面,DeepSeek的表现同样令人印象深刻。通过联网搜索功能,DeepSeek能够整理出详细的事件表,并展示清晰的思考过程。日常使用中,用户发现该模型对中国古代文化如生辰八字、奇门遁甲等非常熟悉,且展示了专业的思考过程。
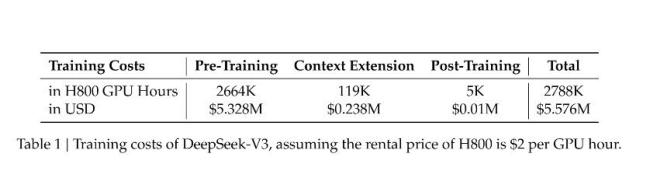
DeepSeek之所以能以较低的成本训练出高性能模型,是因为它摒弃了传统的监督微调,采用单纯的强化学习训练。这一方法不仅减少了计算资源的需求,还观察到了模型的“顿悟时刻”。在处理复杂问题时,模型会重新评估初步方法并分配更多思考时间,显示出高级的问题解决策略。
DeepSeek团队由清华大学和北京大学的应届生和实习生主导,平均年龄不足26岁。这种自下而上的创新文化与OpenAI早期类似。面壁智能首席科学家刘知远认为,DeepSeek的成功证明了通过有限资源的高效利用可以实现以少胜多,缩小了中美在AI领域的差距。未来发展路径尚不明确,仍需百倍努力探出新路。