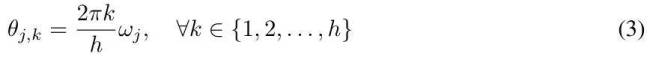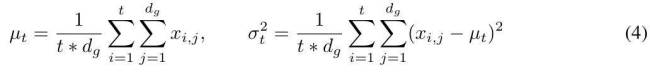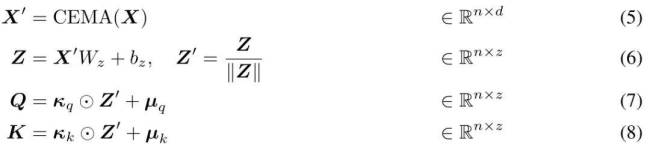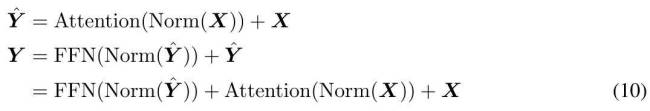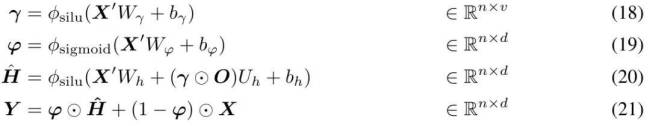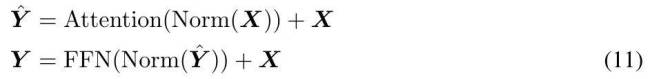谷歌和Meta相继在无限长上下文建模领域展开角逐。Transformer模型因二次复杂度及对长序列处理的局限性,尽管已有线性注意力和状态空间模型等次二次解决方案,但其预训练效率和下游任务准确性仍不尽人意。谷歌近期推出的Infini-Transformer通过创新方法,使大型语言模型能够处理无限长输入,且无需增加内存与计算需求,引发业界关注。

紧随其后,Meta携手南加州大学、CMU、UCSD等研发团队,推出了名为MEGALODON的神经架构,同样致力于无限长文本的高效序列建模,上下文长度无任何限制。MEGALODON在MEGA架构基础上,引入了复数指数移动平均(CEMA)、时间步归一化层、归一化注意力机制及具备双特征的预归一化残差配置等技术组件,旨在提升模型能力和稳定性。

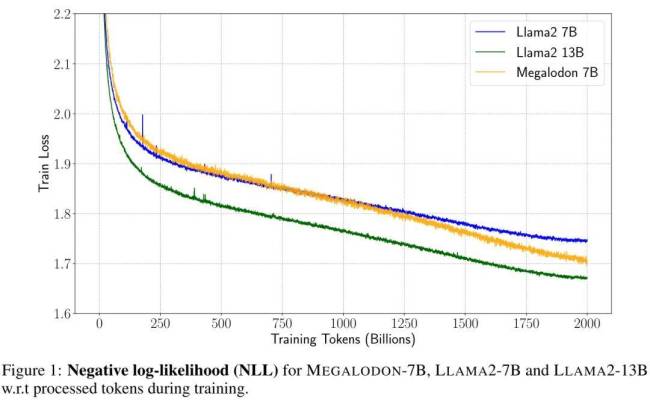
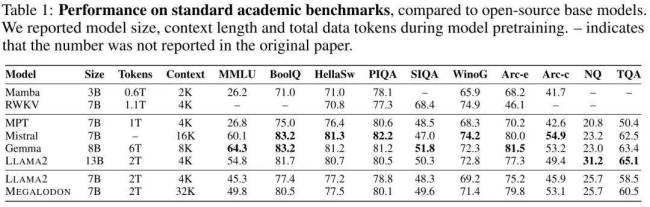
在与LLAMA2的对比试验中,拥有70亿参数、经过2万亿训练token的MEGALODON展现出超越Transformer的效率优势。其训练损失为1.70,介于LLAMA2-7B(1.75)与13B(1.67)之间。一系列基准测试进一步证实了MEGALODON在不同任务与模式中相对于Transformers的显著改进。
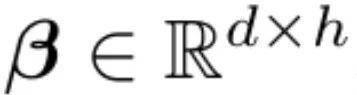
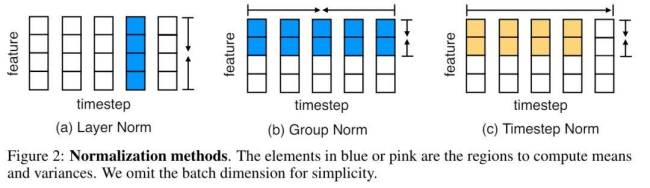
MEGALODON的核心改进在于对MEGA架构的优化,利用门控注意力机制与经典指数移动平均法。为增强大规模长上下文预训练的能力与效率,研究者引入了CEMA,将MEGA中的多维阻尼EMA扩展至复数域;并设计了时间步归一化层,将组归一化应用于自回归序列建模,实现沿顺序维度的归一化。此外,通过预归一化与两跳残差配置调整,以及将输入序列分块为固定块,确保了模型训练与推理过程中的线性计算与内存复杂性。
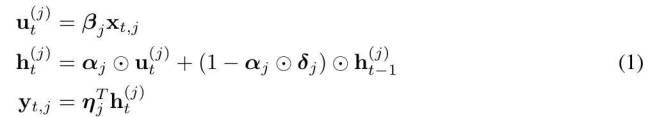
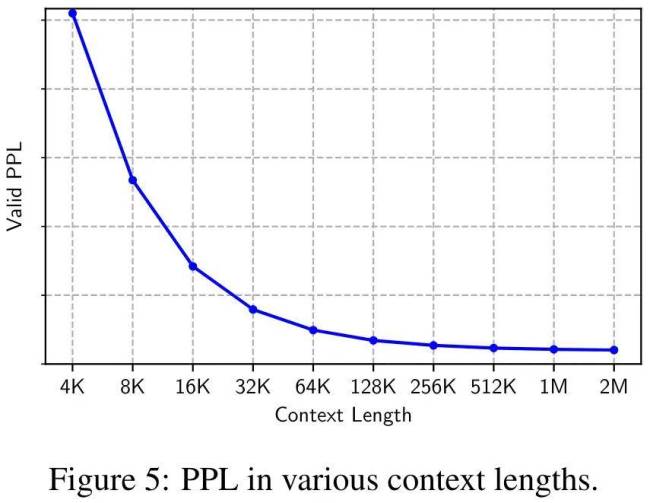
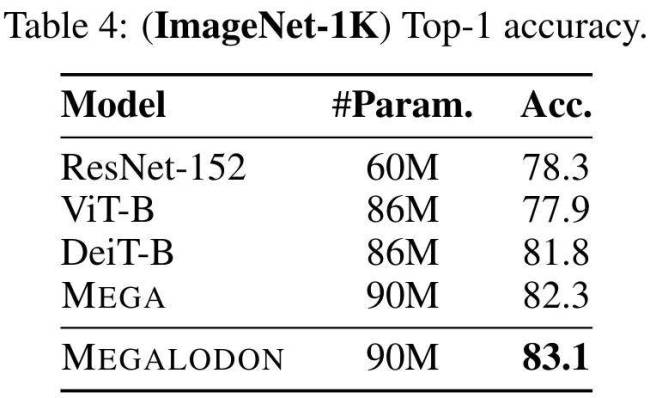
在与LLAMA2的直接较量中,MEGALODON-7B在同等数据与计算资源条件下,训练困惑度显著低于最先进的Transformer变体。针对长上下文建模能力的评估涵盖了从2M的多种上下文长度到Scrolls中的长上下文QA任务,充分证明了MEGALODON处理无限长度序列的能力。此外,在LRA、ImageNet、Speech Commands、WikiText-103和PG19等中小型基准测试中,MEGALODON在体量与多模态处理方面展现卓越性能。

论文详细介绍了MEGALODON的技术创新,包括对MEGA架构中关键组件的回顾及存在问题的探讨。为解决MEGA面临的表达能力受限、架构差异及无法大规模预训练等问题,研究者创新提出CEMA,将多维阻尼EMA扩展至复数域;引入时间步归一化,通过计算累积均值与方差,将组归一化扩展至自回归情况;定制归一化注意力机制以提升稳定性;并设计具有Two-hop残差的预范数结构,有效应对模型规模扩大带来的预归一化不稳定问题。

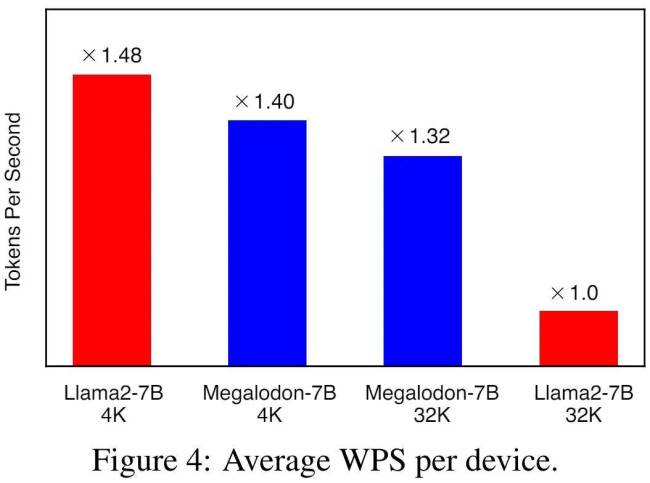
实验结果显示,MEGALODON在长上下文序列建模的可扩展性与效率上表现出色。在相同训练token下,MEGALODON-7B的负对数似然(NLL)优于LLAMA2-7B,显示出更高的数据效率。在不同上下文长度下的WPS(word/token per second)对比中,MEGALODON-7B在处理长上下文时速度明显快于LLAMA2-7B,印证了其在长上下文预训练中的计算效率优势。
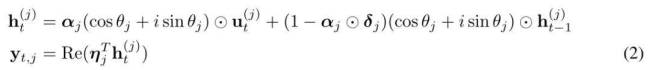
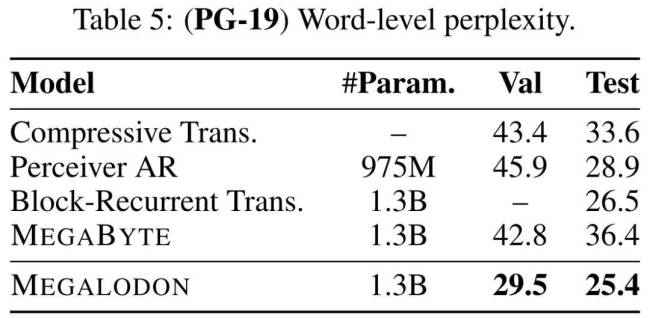
在各项基准测试中,MEGALODON均展现出优秀性能,无论是在短上下文任务,还是长上下文任务,以及指令微调、中等规模基准评估(如ImageNet-1K图像分类与PG-19文本生成)等方面,MEGALODON均取得优异成绩,部分甚至超越已使用RLHF进行对齐微调的模型。这些成果充分验证了MEGALODON在无限长上下文建模领域的先进性与广泛应用潜力。